What are It Team metrics?
Crafting the perfect It Team metrics can feel overwhelming, particularly when you're juggling daily responsibilities. That's why we've put together a collection of examples to spark your inspiration.
Copy these examples into your preferred app, or you can also use Tability to keep yourself accountable.
Find It Team metrics with AI
While we have some examples available, it's likely that you'll have specific scenarios that aren't covered here. You can use our free AI metrics generator below to generate your own strategies.
Examples of It Team metrics and KPIs
Metrics for Monitoring System Performance
1. Time to Detect Issues
The duration it takes to identify technical issues from the moment they arise
What good looks like for this metric: Less than 1 minute
Ideas to improve this metric- Implement real-time monitoring tools
- Set up automated alerts
- Regularly update system documentation
- Conduct routine system audits
- Train staff on quick issue identification
2. System Availability Coverage
The extent to which systems are monitored for availability and functionality
What good looks like for this metric: Coverage for all critical systems
Ideas to improve this metric- Expand monitoring tools to cover more systems
- Integrate with third-party monitoring solutions
- Define critical systems and prioritise them
- Ensure redundancy for critical systems
- Regularly review and update system coverage
3. Data Refresh Rate
The frequency at which system data is updated to reflect the latest information
What good looks like for this metric: Refresh every 10 seconds or less
Ideas to improve this metric- Optimise data processing algorithms
- Utilise caching strategies effectively
- Upgrade hardware for better performance
- Ensure efficient data querying
- Regularly test data refresh processes
4. Incident Resolution Time
The time taken to resolve issues once they are detected
What good looks like for this metric: Within 1 hour
Ideas to improve this metric- Streamline incident response processes
- Improve inter-department communication
- Conduct regular incident response training
- Have a clear escalation path
- Invest in advanced diagnostic tools
5. User Satisfaction Score
A feedback metric showing user satisfaction with system performance and uptime
What good looks like for this metric: Above 85%
Ideas to improve this metric- Conduct regular user feedback surveys
- Improve user interface and experience
- Regularly update users on system status
- Address user complaints swiftly
- Provide clear user support channels
Metrics for Business Software Installation
1. Installation Time
Time taken from the initiation to the completion of the software module installation
What good looks like for this metric: Typically 1 to 3 hours
Ideas to improve this metric- Ensure all prerequisites are met before starting
- Use automated installation scripts
- Perform a test installation prior to the actual installation
- Ensure high-speed internet connection
- Allocate experienced IT personnel
2. Installation Success Rate
Percentage of installations completed without errors
What good looks like for this metric: 95% or higher
Ideas to improve this metric- Conduct thorough pre-installation checks
- Follow a detailed installation guide
- Keep software and system dependencies updated
- Use error-checking tools during installation
- Engage vendor support for troubleshooting
3. User Acceptance
Percentage of users satisfied with the new software module post-installation
What good looks like for this metric: 85% or higher satisfaction rate
Ideas to improve this metric- Provide comprehensive user training
- Gather user feedback post-installation
- Resolve any issues promptly
- Ensure the software aligns with user needs
- Encourage user involvement in the testing phase
4. Downtime During Installation
Amount of system downtime incurred during the software installation
What good looks like for this metric: Less than 30 minutes
Ideas to improve this metric- Schedule installations during off-peak hours
- Perform installations in stages
- Develop a backup plan for critical functions
- Communicate expected downtime to stakeholders
- Optimise system resources before installation
5. Installation Cost
Total cost associated with the installation process, including labor and resources
What good looks like for this metric: $500 to $2,000
Ideas to improve this metric- Negotiate service contracts
- Utilise in-house expertise where possible
- Opt for bundled service packages
- Regularly review and optimise resource allocation
- Plan and budget accurately in advance
Metrics for Business Systems Support
1. Percentage of Systems Fully Functional
Measures the percentage of business systems across departments that are fully functional without any issues
What good looks like for this metric: 90-95%
Ideas to improve this metric- Implement regular system maintenance schedules
- Upgrade outdated software and hardware
- Conduct frequent system audits
- Train staff on system usage and troubleshooting
- Establish a rapid response team for critical issues
2. Average System Downtime
Calculates the average time that business systems are non-operational
What good looks like for this metric: Less than 1 hour per month
Ideas to improve this metric- Optimize backup and recovery processes
- Use automated monitoring tools
- Schedule updates during off-peak hours
- Develop and test robust disaster recovery plans
- Enhance infrastructure reliability with redundancy measures
3. Support Request Resolution Time
Measures the average time taken to resolve support requests from different departments
What good looks like for this metric: Less than 4 hours
Ideas to improve this metric- Set clear priority levels for support tickets
- Implement a ticketing system with tracking capabilities
- Provide customer service training for IT support staff
- Create a comprehensive FAQ and knowledge base
- Encourage self-service for common issues
4. User Satisfaction Score
Summarises user feedback on their satisfaction with systems support
What good looks like for this metric: Above 80%
Ideas to improve this metric- Conduct regular satisfaction surveys
- Analyse feedback to identify common issues
- Engage users in system improvement discussions
- Provide transparent updates on resolution progress
- Recognise and reward high-performance support teams
5. Frequency of System Changes
Tracks how frequently systems undergo significant updates or changes
What good looks like for this metric: Monthly or quarterly updates
Ideas to improve this metric- Plan updates based on user feedback and needs
- Test updates thoroughly in a controlled environment
- Communicate changes effectively to users
- Incorporate user feedback for improvements
- Balance system stability and innovation
Metrics for Windows and VMWare Server Support
1. First Call Resolution Rate
Percentage of issues resolved on the first call without escalation
What good looks like for this metric: 70-80%
Ideas to improve this metric- Provide comprehensive training for team members
- Implement a robust knowledge base
- Utilise remote access tools for rapid solutions
- Ensure clear communication during ticket handling
- Optimise ticket categorisation for swift allocations
2. Average Ticket Resolution Time
Average time taken to resolve support tickets
What good looks like for this metric: Less than 24 hours
Ideas to improve this metric- Enhance prioritisation of critical tickets
- Streamline internal workflows
- Employ ticketing software with automation features
- Offer frequent skill-improving sessions
- Regularly review ticket handoff processes
3. Customer Satisfaction Score
Rating provided by customers after resolution
What good looks like for this metric: Above 90%
Ideas to improve this metric- Solicit feedback through post-service surveys
- Provide personalised support where applicable
- Encourage proactive follow-ups with customers
- Analyse feedback data to identify improvement areas
- Reward team members demonstrating high satisfaction scores
4. Ticket Backlog
Number of unresolved tickets over a specified time period
What good looks like for this metric: Less than 10% of total tickets
Ideas to improve this metric- Regularly audit ticket queue for overdue items
- Implement weekly backlog reviews
- Balance team workload to prevent overloads
- Develop standard operating procedures for common issues
- Encourage team accountability for assigned tickets
5. Service Uptime
Percentage of time the server environment is operational and available
What good looks like for this metric: 99.9%
Ideas to improve this metric- Conduct regular system health checks
- Implement proactive monitoring systems
- Establish a thorough disaster recovery plan
- Schedule routine maintenance during off-peak hours
- Ensure redundancy for critical systems
Metrics for IT Department Efficiency
1. Incident Response Time
The average time it takes for the IT department to respond to an incident after it is reported.
What good looks like for this metric: 30 minutes to 1 hour
Ideas to improve this metric- Implement automated alert systems
- Conduct regular training sessions
- Set up a 24/7 support team
- Streamline incident escalation processes
- Utilise incident management tools
2. First Contact Resolution Rate
The percentage of IT issues resolved during the first contact with the user.
What good looks like for this metric: 70% to 80%
Ideas to improve this metric- Enhance self-service tools and resources
- Improve knowledge base quality
- Conduct specialised training for support staff
- Implement a feedback loop for continuous improvement
- Use advanced diagnostic tools
3. System Uptime
The percentage of time that IT systems are operational and available for use.
What good looks like for this metric: 99% to 99.9%
Ideas to improve this metric- Regularly update and patch systems
- Implement high availability solutions
- Conduct regular system monitoring
- Perform routine maintenance checks
- Use redundant systems
4. User Satisfaction Score
The average satisfaction rating given by users after IT services are provided.
What good looks like for this metric: 4.0 to 4.5 out of 5
Ideas to improve this metric- Offer regular customer service training
- Obtain user feedback and act on it
- Enhance communication channels
- Implement a user-friendly ticketing system
- Provide regular updates to users
5. Mean Time to Repair (MTTR)
The average time taken to fully repair an IT issue after it is reported.
What good looks like for this metric: 2 to 4 hours
Ideas to improve this metric- Improve diagnostic procedures
- Use automated repair tools
- Maintain an updated inventory of spare parts
- Enhance collaboration between IT teams
- Conduct thorough post-incident reviews
Metrics for Monitor data growth accuracy
1. Total Data Volume
The total amount of data stored in a database or system, measured in gigabytes or terabytes
What good looks like for this metric: Evaluated monthly; varies by industry
Ideas to improve this metric- Regularly audit stored data
- Use data compression techniques
- Implement data archiving policies
- Evaluate data storage solutions
- Automate data clean-up processes
2. Growth Rate of Data Volume
The percentage increase in data over a specific period, typically month-over-month
What good looks like for this metric: Generally should not exceed 5% monthly
Ideas to improve this metric- Review data input processes
- Set growth targets
- Analyse growth trends
- Identify unnecessary data accumulation
- Implement stricter data entry policies
3. Percentage of Duplicate Records
The proportion of records that appear more than once in a database
What good looks like for this metric: Aim for less than 1% duplication
Ideas to improve this metric- Use data deduplication tools
- Standardise data entry fields
- Conduct regular data audits
- Train staff on data entry
- Implement unique identifiers
4. Data Accuracy Rate
The percentage of data that is correct and free from error
What good looks like for this metric: Should be above 95%
Ideas to improve this metric- Conduct regular data quality checks
- Provide data entry training
- Utilise automated validation tools
- Standardise data formats
- Implement error logging
5. Record Completeness Rate
The percentage of records that have all required fields filled out
What good looks like for this metric: Should remain above 90%
Ideas to improve this metric- Ensure all required fields are filled
- Review and update data entry templates
- Implement data input checks
- Improve user data input interfaces
- Incentivise complete data entry
Metrics for IT Service Agreement Compliance
1. % Compliance with SLA
The percentage of time that IT services are delivered within the predefined terms of the service level agreement
What good looks like for this metric: 90-99%
Ideas to improve this metric- Increase training for service delivery teams
- Enhance monitoring and reporting tools
- Conduct regular SLA reviews and updates
- Ensure clear communication of SLA terms to all stakeholders
- Implement more efficient service processes
2. Response Time to Incidents
The amount of time taken to respond to IT incidents from the time they are reported
What good looks like for this metric: 30 minutes
Ideas to improve this metric- Automate incident alert systems
- Improve resource allocation during peak times
- Provide advanced training for incident management
- Utilise real-time monitoring and dashboards
- Regularly measure and adjust response strategies
3. Resolution Time to Incidents
The amount of time taken to resolve IT incidents from the time they are reported
What good looks like for this metric: 4 hours
Ideas to improve this metric- Implement root cause analysis for recurring issues
- Enhance collaboration across IT teams
- Use advanced diagnostic and repair tools
- Schedule regular knowledge sharing sessions
- Review and optimise workflows for resolution
4. User Satisfaction Rate
Percentage of users satisfied with the IT services provided in accordance with the SLA
What good looks like for this metric: 85-90%
Ideas to improve this metric- Conduct regular satisfaction surveys
- Implement feedback loops for continuous improvement
- Analyse survey data for actionable insights
- Ensure rapid follow-up to any user complaints
- Continuously train staff in customer service skills
5. Change Success Rate
The percentage of changes to the IT system that are successful and do not result in incidents
What good looks like for this metric: 95%
Ideas to improve this metric- Perform rigorous change testing before implementation
- Develop clear guidelines for change management
- Ensure thorough documentation of all changes
- Utilise change advisory boards to approve changes
- Conduct post-change reviews to identify improvement areas
Metrics for Automation in Business Units
1. Process Automation Rate
Percentage of business processes currently automated compared to the total processes possible
What good looks like for this metric: 20-30%
Ideas to improve this metric- Conduct a thorough process audit
- Identify repetitive manual tasks
- Leverage robotic process automation tools
- Invest in staff training for technology adoption
- Establish clear automation goals
2. Time Saved Through Automation
Amount of time saved as a result of implementing automation in business processes
What good looks like for this metric: 10-50% time reduction
Ideas to improve this metric- Analyse current process time expenditures
- Prioritise automation of most time-consuming tasks
- Collaborate with departments to streamline processes
- Continuously measure time savings
- Optimise processes post-automation
3. Cost Reduction Due to Automation
Financial savings accrued from reducing manual labour and errors via automation
What good looks like for this metric: 15-30% cost reduction
Ideas to improve this metric- Assess cost structures before automation
- Focus on high-cost processes for automation
- Use cost-effective automation solutions
- Regularly evaluate cost savings
- Scale successful automation projects
4. Error Reduction Rate
Decrease in errors in business processes as a result of automation
What good looks like for this metric: 30-70% reduction in errors
Ideas to improve this metric- Identify error-prone processes
- Use high-accuracy automation technologies
- Implement continuous error monitoring systems
- Train employees on new automated systems
- Review error rates regularly to refine processes
5. Employee Satisfaction with Automation
Degree to which employees are satisfied with the automation tools and their impact on work
What good looks like for this metric: 70-85% satisfaction rate
Ideas to improve this metric- Conduct employee satisfaction surveys
- Provide comprehensive training sessions
- Encourage employee feedback on automation tools
- Create a support system for employees
- Highlight benefits of automation to employees
Metrics for Security and Compliance
1. Device Compliance Rate
Measures the percentage of devices that meet compliance requirements for security standards.
What good looks like for this metric: 95% compliance rate
Ideas to improve this metric- Conduct regular compliance audits
- Update security policies frequently
- Train employees on compliance requirements
- Automate compliance checks
- Use endpoint protection software
2. Threat Detection Time
The average time taken to detect a security threat on an end-user device.
What good looks like for this metric: Under 24 hours
Ideas to improve this metric- Implement real-time monitoring
- Utilise AI-powered threat detection tools
- Regularly update threat databases
- Conduct regular security tests
- Enable fast response procedures
3. Patch Management Timeliness
The average time taken to apply security patches to end-user devices.
What good looks like for this metric: Within 72 hours
Ideas to improve this metric- Automate patch deployment
- Schedule regular update checks
- Prioritise critical patches
- Maintain a patch inventory
- Verify patch installations regularly
4. Data Encryption Rate
The percentage of end-user devices that have encryption enabled for data storage.
What good looks like for this metric: 100% encryption rate
Ideas to improve this metric- Enforce encryption policies
- Provide encryption tools
- Train users on encryption benefits
- Audit encryption compliance
- Utilise full-disk encryption solutions
5. Incident Response Rate
Measures the effectiveness and speed of response when a security incident occurs.
What good looks like for this metric: 90% incidents resolved within 48 hours
Ideas to improve this metric- Establish a dedicated response team
- Develop a detailed incident response plan
- Run regular incident response drills
- Utilise automated incident detection systems
- Review response procedures post-incident
Metrics for Showcase Team Performance
1. Incident Response Time
The average time taken by the team to respond to reported incidents
What good looks like for this metric: Less than 30 minutes
Ideas to improve this metric- Implement automated alert systems
- Conduct regular training on incident management
- Set clear response time goals
- Prioritise incidents based on severity
- Review and analyse past response times for improvement
2. System Uptime
The percentage of time systems are operational and available
What good looks like for this metric: 99.9% or above
Ideas to improve this metric- Conduct regular system maintenance
- Implement redundancy solutions
- Perform load testing to understand capacity
- Monitor system health in real-time
- Establish a disaster recovery plan
3. User Satisfaction Score
Survey score given by users based on their satisfaction with team support
What good looks like for this metric: 8 out of 10 or higher
Ideas to improve this metric- Regularly survey users to gather feedback
- Implement a user-friendly ticketing system
- Ensure timely updates to users
- Provide training in customer service skills
- Analyse feedback and address common issues
4. Ticket Resolution Rate
The percentage of tickets resolved within the agreed service level agreement (SLA)
What good looks like for this metric: 95% or higher
Ideas to improve this metric- Establish clear SLAs for ticket resolution
- Use ticketing software to prioritise workload
- Encourage team collaboration on complex issues
- Track pending tickets and address bottlenecks
- Hold regular reviews on ticket performance
5. Change Success Rate
The percentage of system changes that are successfully implemented without causing incidents
What good looks like for this metric: 90% or higher
Ideas to improve this metric- Establish a change management process
- Conduct risk assessments before changes
- Communicate changes to all stakeholders
- Provide training on implementing changes
- Review and learn from failed changes
Metrics for Service Health Evaluation
1. Uptime Percentage
Measures the amount of time the service is up and running without interruptions. Calculated by dividing the total operational minutes by the total minutes in a period.
What good looks like for this metric: 99.9% or higher
Ideas to improve this metric- Implement redundancy systems
- Use robust monitoring tools
- Conduct regular maintenance
- Train staff for quick incident response
- Opt for reliable service providers
2. Response Time
The time it takes for the service to respond to a user action or request. Typically measured in milliseconds or seconds.
What good looks like for this metric: Less than 200ms
Ideas to improve this metric- Optimize server configurations
- Use a content delivery network
- Streamline code and queries
- Enhance database performance
- Regularly audit application performance
3. Error Rate
The percentage of failed requests in relation to the total number of service requests.
What good looks like for this metric: Less than 1%
Ideas to improve this metric- Implement detailed logging
- Enhance debugging processes
- Regular code reviews
- Continuous service testing
- Deploy robust error handling
4. Customer Satisfaction Score (CSAT)
A measurement derived from customer feedback focusing on satisfaction with the service, typically collected via surveys.
What good looks like for this metric: 80% or higher
Ideas to improve this metric- Enhance user experience design
- Implement customer feedback loops
- Resolve issues promptly
- Provide user-friendly interfaces
- Conduct regular user training
5. Transaction Success Rate
The percentage of successful transactions completed without any errors or failures.
What good looks like for this metric: 95% or higher
Ideas to improve this metric- Optimize transactional workflow
- Enhance payment gateway reliability
- Continuously monitor transaction logs
- Implement strong authentication mechanisms
- Regularly update and test payment procedures
Metrics for Help Desk Performance Tracking
1. Average Ticket Resolution Time
The average time taken to resolve a ticket from the moment it's opened until it's closed. This measures efficiency in handling support requests.
What good looks like for this metric: 24 hours or less
Ideas to improve this metric- Automate repetitive tasks
- Improve staff training
- Streamline ticket prioritisation
- Use performance-boosting software
- Implement a robust knowledge base
2. First Contact Resolution Rate
The percentage of tickets resolved during the initial contact with the help desk. A high rate indicates effective support processes.
What good looks like for this metric: 70-75%
Ideas to improve this metric- Equip staff with decision-making power
- Enhance customer service scripts
- Provide ongoing training
- Utilise integrated support tools
- Conduct regular process reviews
3. Customer Satisfaction Score (CSAT)
A measure of customer satisfaction with the resolution of their support tickets, often gathered via surveys after ticket closure.
What good looks like for this metric: 85% or higher
Ideas to improve this metric- Conduct feedback analysis
- Enhance communication channels
- Personalise support interactions
- Reduce wait times
- Regular staff empathy training
4. Ticket Volume Per Channel
Tracking the number of tickets received via each support channel (e.g., email, phone, chat) helps understand customer preferences.
What good looks like for this metric: Balanced distribution across channels
Ideas to improve this metric- Promote diverse contact options
- Evaluate efficiencies of each channel
- Optimise routing based on traffic
- Balance workforce allocation
- Improve multi-channel integration
5. Backlog Ratio
The ratio of unresolved tickets at any time, measuring how well the help desk manages its workload.
What good looks like for this metric: 10% or lower
Ideas to improve this metric- Implement extra shifts during peak times
- Regularly review and close stale tickets
- Prioritise high-impact cases
- Automate low-priority ticket handling
- Improve resource planning
Metrics for Device Usage Analysis
1. Data Processing Throughput
Measures the amount of data processed successfully within a given time frame, typically in gigabytes per second (GB/s)
What good looks like for this metric: Varies by system but often >1 GB/s for high-performing systems
Ideas to improve this metric- Increase hardware capabilities
- Optimise software algorithms
- Implement data compression techniques
- Use parallel processing
- Upgrade network infrastructure
2. Latency
Time taken from input to desired data processing action, measured in milliseconds (ms)
What good looks like for this metric: <100 ms for high-performing systems
Ideas to improve this metric- Enhance server response time
- Minimise data travel distance
- Optimise application code
- Utilise content delivery networks
- Implement load balancers
3. Error Rate
Percentage of errors during data processing compared to total operations, measured as a %
What good looks like for this metric: <5% for acceptable performance
Ideas to improve this metric- Implement error-handling codes
- Train systems with more robust datasets
- Regularly update software
- Conduct thorough system testing
- Improve data input validity checks
4. Disk I/O Rate
Measures read and write operations per second on storage devices, expressed in IOPS (input/output operations per second)
What good looks like for this metric: >10,000 IOPS for SSDs, lower for HDDs
Ideas to improve this metric- Upgrade to faster storage solutions
- Redistribute data loads
- Increase cache sizes
- Use faster file systems
- Optimise database queries
5. Resource Utilisation
Percentage of CPU, memory, and network bandwidth being used, expressed as a %
What good looks like for this metric: 75-85% for efficient resource use
Ideas to improve this metric- Perform regular system monitoring
- Distribute workloads more evenly
- Implement scalable cloud solutions
- Prioritise critical processes
- Utilise virtualisation
Metrics for Threat and Incident Analysis
1. Incident Detection Time
The time taken from the moment a threat is detected to the initiation of an incident response
What good looks like for this metric: Typically less than 15 minutes
Ideas to improve this metric- Implement automated alerting systems
- Conduct regular threat hunting exercises
- Enhance staff training on threat identification
- Integrate with advanced threat intelligence platforms
- Utilise machine learning for anomaly detection
2. Containment Time
The duration between detection and containment of a threat to minimise its spread and impact
What good looks like for this metric: Ideally under 30 minutes
Ideas to improve this metric- Automate endpoint isolation procedures
- Improve network segmentation
- Establish predefined incident response playbooks
- Regularly test response strategies
- Foster collaboration between IT and security teams
3. False Positive Rate
The percentage of alerts that are incorrectly identified as threats
What good looks like for this metric: Should be below 5%
Ideas to improve this metric- Refine rule sets and detection algorithms
- Incorporate feedback loops to learn from past alerts
- Leverage threat intelligence feeds
- Enhance contextual information in alerts
- Invest in more precise detection technologies
4. Number of Lateral Movement Attempts
Counts of attempts by threats to move laterally within a network after initial access
What good looks like for this metric: Ideally zero attempts
Ideas to improve this metric- Deploy micro-segmentation techniques
- Monitor for unusual access patterns
- Strengthen user privilege controls
- Use lateral movement detection tools
- Conduct regular security audits and penetration testing
5. Incident Recovery Time
The time required to fully restore systems and operations post-incident
What good looks like for this metric: Within 24 hours for minor incidents
Ideas to improve this metric- Maintain regular backups and restore procedures
- Invest in resilient infrastructure
- Document and streamline recovery processes
- Facilitate cross-department cooperation
- Regularly update and test recovery plans
Metrics for Handling Log Files
1. Throughput
Measures the number of log files processed per minute to ensure the service meets the 40k requirement
What good looks like for this metric: 40,000 log files per minute
Ideas to improve this metric- Optimize log processing algorithms
- Upgrade server hardware
- Use a load balancer to distribute requests
- Implement batch processing for logs
- Minimize unnecessary logging
2. Latency
Measures the time it takes to process each log file from receipt to completion
What good looks like for this metric: Less than 100 milliseconds
Ideas to improve this metric- Streamline data pathways
- Prioritise real-time log processing
- Identify and remove processing bottlenecks
- Utilise caching mechanisms
- Optimize database queries
3. Error Rate
Tracks the percentage of log files that are not processed correctly
What good looks like for this metric: Less than 1%
Ideas to improve this metric- Implement robust error handling mechanisms
- Conduct regular integration tests
- Utilise validation before processing logs
- Enhance logging system for transparency
- Review and improve exception handling
4. Resource Utilisation
Measures the use of CPU, memory, and network to ensure efficient handling of logs
What good looks like for this metric: Below 80% for CPU and memory utilisation
Ideas to improve this metric- Optimize code for better performance
- Implement vertical or horizontal scaling
- Regularly monitor and adjust resource allocation
- Use lightweight libraries or frameworks
- Run performance diagnostics regularly
5. System Uptime
Tracks the percentage of time the system is operational and able to handle log files
What good looks like for this metric: 99.9% uptime
Ideas to improve this metric- Implement redundancies in infrastructure
- Schedule regular maintenance
- Monitor system health continuously
- Use reliable cloud services
- Establish quick recovery protocols
Tracking your It Team metrics
Having a plan is one thing, sticking to it is another.
Having a good strategy is only half the effort. You'll increase significantly your chances of success if you commit to a weekly check-in process.
A tool like Tability can also help you by combining AI and goal-setting to keep you on track.
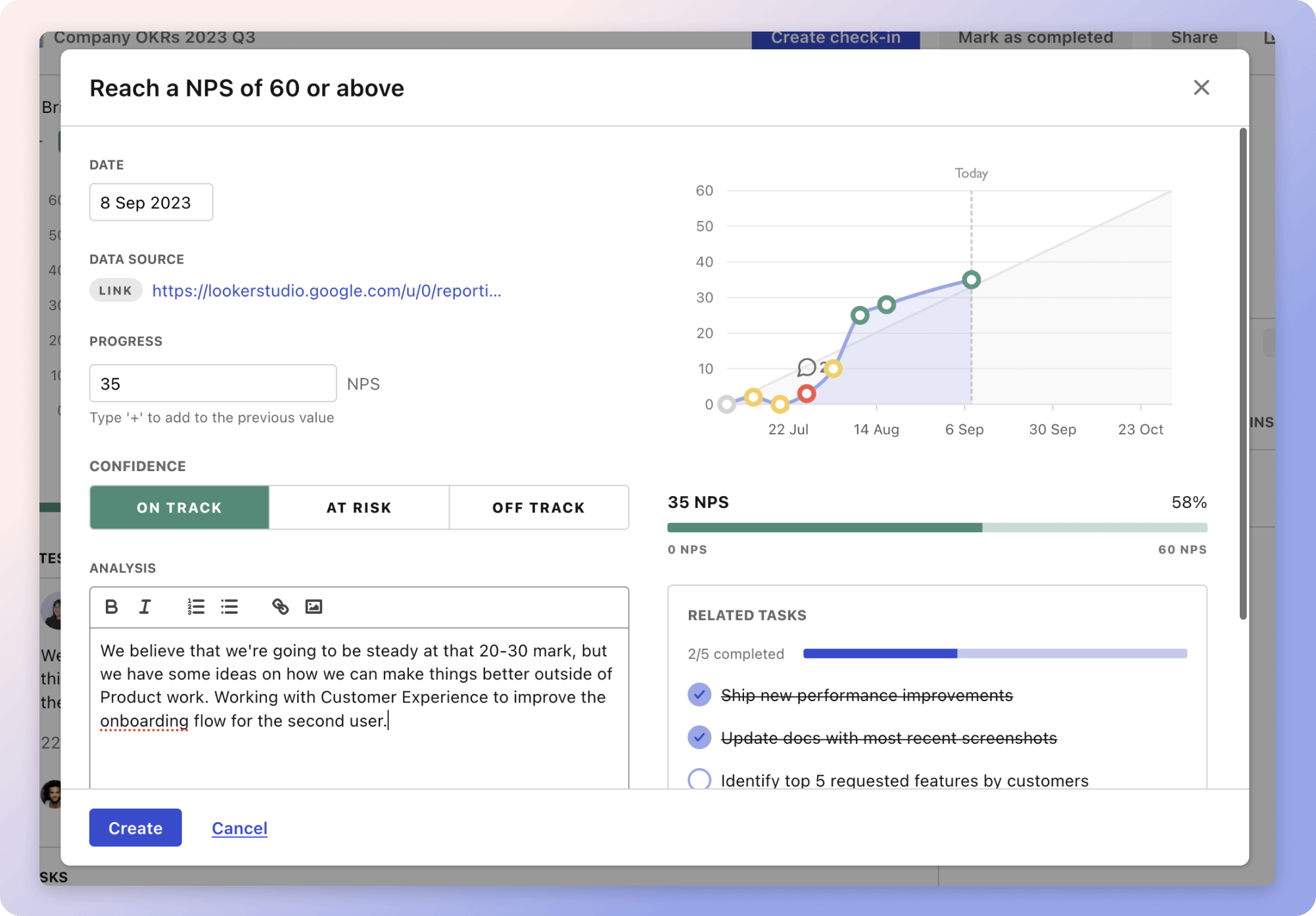 Tability's check-ins will save you hours and increase transparency
Tability's check-ins will save you hours and increase transparencyMore metrics recently published
We have more examples to help you below.
 The best metrics for Increase Calls Through Google My Business
The best metrics for Increase Calls Through Google My Business- The best metrics for GRC MSSP Compliance
- The best metrics for Reduce Courier Costs
- The best metrics for Reducing Courier Costs
- The best metrics for Operations Management Success
- The best metrics for Ensuring sticker quality
Planning resources
OKRs are a great way to translate strategies into measurable goals. Here are a list of resources to help you adopt the OKR framework:
- To learn: What are OKRs? The complete 2024 guide
- Blog posts: ODT Blog
- Success metrics: KPIs examples